
BIOMOLECULES
INTRODUCTION
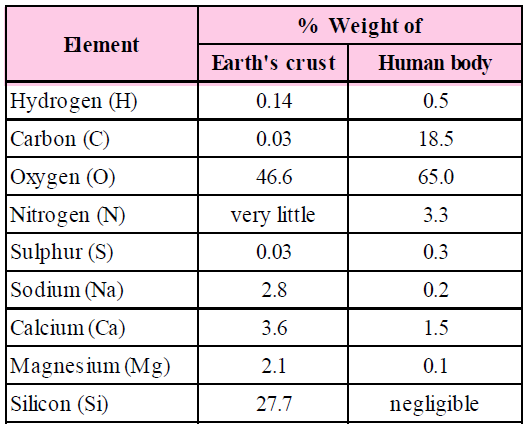
- An analysis of plant tissues, animal tissues and microbial mass indicates that they are made up of almost similar types of elements and compounds.
- Four elements: carbon, hydrogen, oxygen and nitrogen constitutes 97–99% of the body of living organisms.
- All compounds or molecules present in living cells are called biomolecules. It includes large macromolecules such as proteins, polysaccharides, lipids and nucleic acids, as well as small molecules such as primary metabolites, secondary metabolites and natural products.
- Only three types of macromolecules, i.e., proteins, nucleic acids and polysaccharides are found in living systems. Lipids, because of their association with membranes, get separated in the macromolecular fraction.
- Biomacromolecules are polymers. These are large sized, high molecular weight complex molecules that are formed by the condensation of biomacromolecules.
- Proteins are heteropolymers made of amino acids. These serve a variety of cellular functions. Many of them are enzymes, antibodies, receptors, hormones and some others are structural proteins.
- Nucleic acids (RNA and DNA) are composed of nucleotides.
- Polysaccharides are components of cell wall in plants, fungi and also of the exoskeleton of arthropods. They also are storage forms of energy (e.g., starch and glycogen).
HOW TO ANALYSE CHEMICAL COMPOSITION
To know what type of organic compounds are found in living organisms, one has to perform a chemical analysis. We can take any living tissue (a vegetable or a piece of liver, etc.) and grind it in trichloroacetic acid (Cl3CCOOH) using a mortar and pestle. We obtain a thick slurry. If we were to strain through a cheesecloth or cotton, we would obtain two fractions. One is called the filtrate or more technically, the acid-soluble pool, and the second, the retentate or the acid-insoluble fraction. Scientists have found thousands of organic compounds in the acid-soluble pool.
A comparison of elements present in non-living and living matter.
PRIMARY AND SECONDARY METABOLITES
Primary metabolites are involved in growth, development, and reproduction of the organisms. The primary metabolite is typically a key component in maintaining normal physiological processes. These are typically formed during the growth phase as a result of energy metabolism, and are very essential for proper growth. E.g., are ethanol, lactic acid, and certain amino acids.
Secondary metabolites are typically organic compounds produced through the modification of primary metabolites. These do not play a role in growth, development, and reproduction like primary metabolites and are typically formed during the end or near the stationary phase of growth. Many of the identified secondary metabolites have a role in ecological function, including defence mechanism(s), by serving as antibiotics and by producing pigments.
MICROMOLECULES
These are molecules of low molecular weight and have higher solubility. These include minerals, water, amino acids, sugars and nucleotides.
ELEMENTS
On the basis of presence and requirement in plants and animals, these are grouped into major (Ca, P, Na, Mg, S, K, N) and minor (Fe, Cu, Co, Mn, Mo, Zn, I) bioelements.
On the basis of functions, these may be of following types :–
- Framework elements : Carbon, oxygen and hydrogen.
- Protoplasmic elements : Proteins, nucleic acids, lipids, chlorophyll, enzymes, etc.
- Balancing elements : Ca, Mg and K.
BIOLOGICAL COMPOUNDS
- Inorganic compounds : Water 80%, inorganic salts 1-3%.
- Organic compounds : Carbohydrates (1.0%), lipids (3.5%), proteins (12.0%), nucleotides (2.0%), other compounds (0.5%).
CELLULAR POOL
Various kinds of biomolecules aggregated and interlinked in a living system is called cellular pool. It includes over 5000 chemicals.
WATER
Major constituent of cell (about 60-90%) and exists in intracellular, intercellular as well as in vacuoles. In cells, it occurs in free state or bound state (KOH, CaOH etc.).
CARBOHYDRATES
E.g., sugars, glycogen (animal starch), plant starch and cellulose.
SOURCE OF CARBOHYDRATE
It is formed during photosynthesis. It exists only in 1% but constitutes 80% of the dry weight of plants.
COMPOSITION
It consists of carbon, hydrogen and oxygen in the ratio CnH2nOn. It is also called saccharide with sugars being the basic components of saccharides.
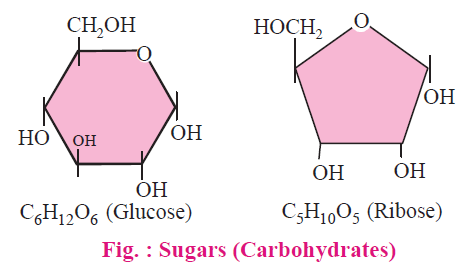
CLASSIFICATION OF CARBOHYDRATES
(A) Monosaccharides
Monosaccharides are colourless, sweet tasting solids that show oxidation, esterification and fermentation. Due to asymmetric carbon, these exist in different isomeric forms. These can rotate polarized light hence are dextrorotatory and laevorotatory.
These are single sugar units which can not be hydrolysed further into smaller carbohydrates. General formula is CnH2nOn, E.g., trioses-3C, (Glyceraldehyde, dihydroxyace-tone etc.), tetroses-4C, pentoses-5C, hexoses-6C etc.
Important Hexoses Glucose : (C6H12O6) are fructose, galactose (important constituent of glycolipids and glycoproteins).
NOTES
Fructose is called fruit sugar (sweetest among natural sugars) and glucose is called “sugar of body” (blood sugar). Normal level of blood glucose is 80-120mg/100ml. If it exceeds then the condition is called “glucosuria”.
(B) Oligosaccharides
It is formed due to condensation of 2–10 monosaccharide units, the oxygen bridge is known as “glycoside linkage” and water molecule is eliminated. The bond may be α and β.
- Disaccharides C12H22O11 : It is composed of two molecules of the same or different monosaccharide units. Also called “double sugars”.
- Maltose : Also called “malt sugar” stored in germinating seeds of barley, oats, etc. It is formed by enzymatic (enzyme amylase) action on starch. It is a reducing sugar.
- Sucrose : “Cane sugar” or “table-sugar”. It is obtained from sugarcane and beetroot and on hydrolysis splits into glucose and fructose.
- Lactose : “Milk sugar’’, present in mammalian milk. On hydrolysis if yields glucose and galactose. Streptococcus lacti converts lactose into lactic acid and causes souring of milk.
- Trisaccharides C18H32O16 : It is composed of three molecules of sugars.
- Raffinose : Found in sugar beet, cotton and in some fungi. It is made up of glucose, fructose and galactose.
- Tetrasaccharides : It is composed of four molecules of the same or different sugars. Stachyose is found in Stachys tubifera. It is made up of two units of galactose, one units of glucose and one unit of fructose.
- Polysaccharides : General formula is (C6H10O5)n formed by condensation of several molecules (300–1000) of monosaccharides.
LIPIDS
- Fat and its derivatives are together known as lipid. The term 'Lipid' was given by German biochemist, Wilhem Bloor for fat and fat like substances.
- Essential constituents are C, H, O but the ratio of hydrogen and oxygen is not 2 : 1. The amount of oxygen is considerably very less.
- Lipids are insoluble in water and soluble in organic solvents like acetones, chloroform, benzene, hot alcohol, ether etc.
- Lipids occur in protoplasm as minute globules. These require less space for storage as compared to carbohydrate because lipid molecule is hydrophobic and condensed.
- Lipids do not form polymer.
- Lipids provide more than double energy as compared to carbohydrates.
- In animals, fat present in the subcutaneous layer and working as food reservoir and shock-absorber.
- Animals store maximum amount of food in the form of lipid.
- Lipids are not strictly macromolecules.
- There are 3 classes of lipids :
- Simple lipids or neutral fats
- Compound or conjugated lipids
- Derived lipids
SIMPLE LIPIDS OR NEUTRAL FATS
- These are esters of long chain fatty acids with various alcohols. In the majority of simple lipids, the alcohol is a trihydroxy sugar alcohol i.e. glycerol.
- Three molecules of fatty acid linked with one molecule of glycerol. The linkage is called “ester bond”, such type of lipids are called triglycerides. Three molecules of water are released during formation of triglycerides (dehydration synthesis).
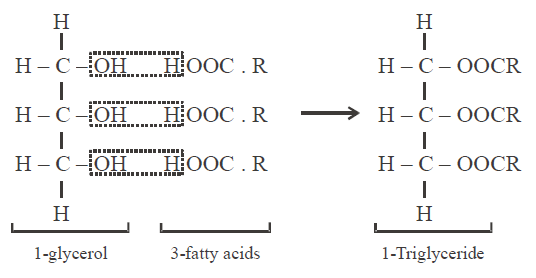
- Similar or different fatty acids participate in the composition of a fat molecule. Simple lipids contain two types of fatty acids :
SATURATED FATTY ACIDS are those in which all the carbon atoms of hydrocarbon chain are saturated with hydrogen atoms.
e.g. Palmitic acid CH3(CH2)14 - COOH
Stearic acid CH3(CH2)16 - COOH
- Simple lipids with saturated fatty acids remain solid at normal room temperature e.g., fats.
- Saturated fatty acids are less reactive so they tend to store in the body and cause obesity.
UNSATURATED FATTY ACIDS are those in which some carbon atoms are not fully occupied by hydrogen atoms.
e.g. Oleic acid CH3(CH2)7CH = CH(CH2)7 – COOH
Linoleic acid CH3(CH2)4 – (CH = CH – CH2)2 – (CH2)6 – COOH
Linolenic acid CH3(CH2) – (CH = CH – (CH2)3 – (CH2)6 – COOH
- Unsaturated fatty acids also called as essential fatty acids because animals are not able to synthesize them.
- Simple lipids with unsaturated fatty acids remain liquid at room temperature e.g., oils.
- Unsaturated fatty acids are more reactive so they tend to metabolise in the body and provide energy.
- Oils with polyunsaturates are recommended by physicians for persons who suffer from high blood cholesterol or cardio-vascular diseases. This is because increasing the proportion of polyunsaturated fatty acids to saturated fatty acids, without raising the fats in the diet tend to lower the cholesterol level in blood.
- Waxes : Waxes are monoglycerides with one molecule of long chain fatty acids and a long chain monohydroxy alcohol. Waxes are more resistant to hydrolysis as compared to triglycerides. Waxes have an important role in protection. They form water insoluble coatings on hair and skin in animals and stem, leaves and fruits of plants.
CONJUGATED OR COMPOUND LIPIDS
PHOSPHOLIPIDS OR PHOSPHATIDE
- It is made of 2 molecules of fatty acid + glycerol + H3PO4 + nitrogenous compounds. Phospholipids are the most abundant type of lipids in protoplasm.
- Phospholipids have both hydrophilic polar end (H3PO4 and nitrogenous compound) and hydrophobic non-polar end (fatty acids). Such molecules are called amphipathic. Due to this property, phospholipids form bimolecular layer in cell membrane.
- Some biologically important phospholipids are as follows :
- Lecithin or phosphatidylcholine : Nitrogenous compound in lecithin is choline. Lecithin occurs in egg yolk, oil seeds and blood. In blood, lecithin functions as carrier molecule. It helps in transportation of other lipids.
- Cephalin or Ethanolamine : Similar to lecithin but the nitrogenous compound is ethanolamine. Cephalin occurs in nervous tissue, egg yolk and blood platelets.
- Sphingolipids or sphingomylins are similar to lecithin but in place of glycerol they contain an amino alcohol sphingosine.
These occur in myelin - sheath of nerves. Other examples of phospholipids are phosphatidyl serine, phosphatidyl inositol, plasmologens.
GLYCOLIPID
It is made of 2 molecules of fatty acid + sphingosine + galactose, e.g. cerebroside which occurs in white matter of the brain.
GANGLIOSIDES
These occur in nerve ganglia and spleen. These also contain N-acetyl neuraminic acid and glucose beside other compounds.
DERIVED LIPIDS
- These are derived from simple or conjugated lipids and are complex in structure. These are insoluble in water and soluble in organic solvents.
- Steroids : Steroids exhibit tetracyclic structure called “Cyclo pentano perhydrophenanthrene nucleus”.
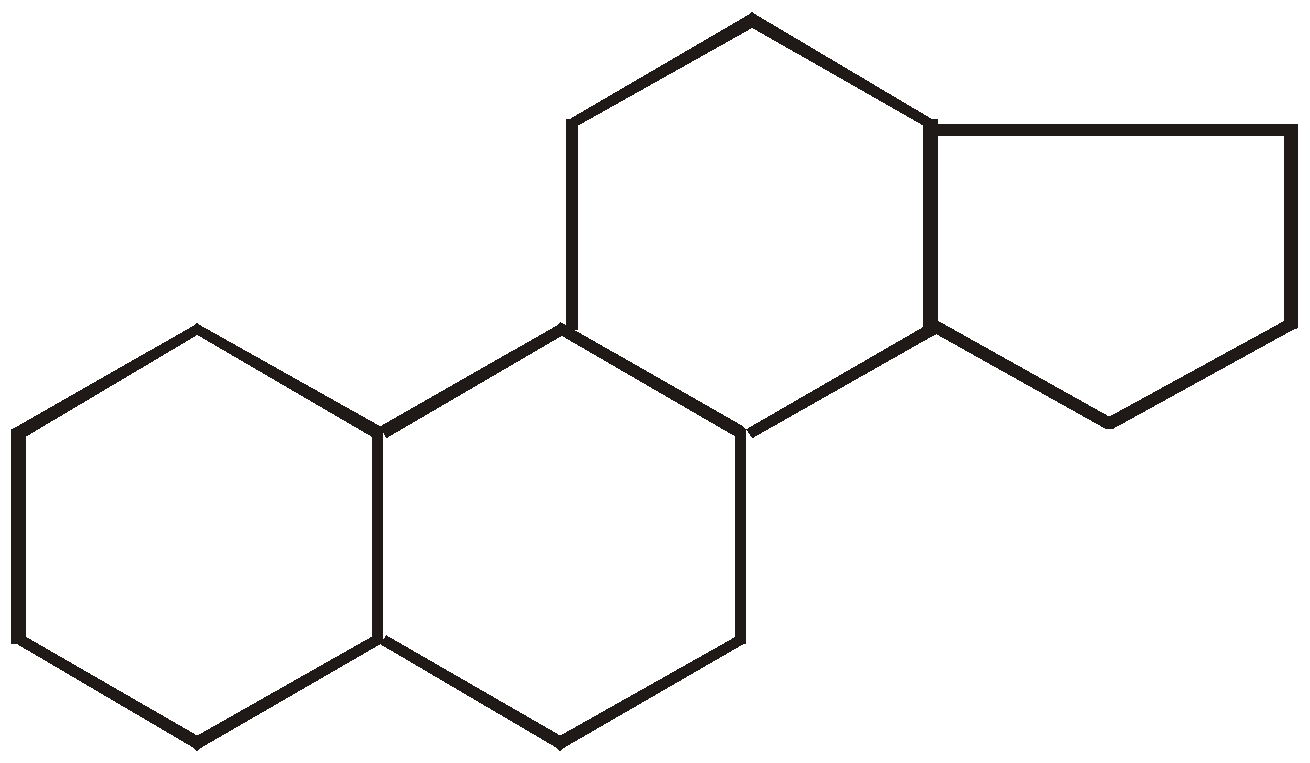
On the basis of functional group, steroids are of two types,
- Sterols : Lipids without straight chains are called sterols. These are composed of fused hydrocarbon rings and long hydrocarbon side chain, E.g., cholesterol.
- Sterones : They are ketonic steroids, E.g., sex hormones, adreno-corticoids, ecdysone hormone of insects, diosgenin obtained from yam plant (Dioscorea) is used in the manufacture of anti-fertility pills.
FUNCTIONS OF LIPIDS
- Oxidation of lipids yield comparatively more energy in the cell than proteins and carbohydrates.
- The oil seeds such as groundnut, mustard, coconut store fats to provide nourishment to the embryo during germination.
- These function as structural constituent i.e., all the membrane system of the cell are made up of lipoproteins.
- Amphipathic lipids are emulsifiers.
- It works as a heat insulator and is used in the synthesis of hormones.
- Fats provide solubility to vitamins A, D, E and K.
MACROMOLECULES
Macromolecules are polymerisation products of micromolecules, having high molecular weight and low solubility. These include mainly polysaccharide, protein and nucleic acids.
POLYSACCHARIDES
These are branched or unbranched polymers of monosaccharides joined by glycosidic bond. Their general formula is (C6H10O5)n. Polysaccharides are amorphous, tasteless and insoluble or only slightly soluble in water and can be easily hydrolysed to monosaccharide units.
TYPES OF POLYSACCHARIDES
- On the basis of structure
- Homopolysaccharides : These are made by polymerisation of single kind of monosaccharides. e.g., starch, cellulose, glycogen, etc.
- Heteropolysaccharides : These are made by condensation of two or more kinds of monosaccharides, e.g., chitin, pectin, etc.
- On the basis of functions
- Food storage polysaccharides : These serve as reserve food, e.g., starch and glycogen.
- Structural polysaccharides : These take part in structural framework of cell wall, e.g., chitin and cellulose.
Glycogen : It is a branched polymer of glucose and contains 30,000 glucose units. It is also called animal starch is found as storage product in blue green algae, slime moulds, fungi and bacteria. It is a non-reducing sugar and gives red colour with iodine. In glycogen, glucose molecules are linked by 1→ 4 glycosidic linkage in straight part and 1 → 6 linkage in the branching part. Glycogen has branch points at about every 8-10 glucose units.
Starch (C6H10O5) : Starch is formed in photosynthesis and function as energy storing substance. It is found abundantly in rice, wheat, legumes, potato, banana, etc. Starch is of two types- Straight chain polysaccharides are known as amylose and branched chain as amylopectin. Both are composed of D–glucose units joined by α-1→ 4 linkage and α-1→ 6 linkage. It is insoluble in water and gives blue colour when treated with iodine.
Inulin : It is also called “dahlia starch”(found in roots). It has unbranched chain of 30 – 35 fructose units linked by β-2→1 glycosidic linkage between 1 and 2 of carbon atom of D– fructose unit.
Cellulose : An important constituent of cell wall (20 – 40%), made up of unbranched chain of 6000 β–D glucose units linked by 1 → 4 glycosidic linkage. It is fibrous, rigid and insoluble in water. It doesn’t give any colour when treated with iodine. It is the most abundant polysaccharide.
Chitin : It is a polyglycol consisting of N-acetyl–D–glucosamine units connected with β-1,4 glycosidic linkage. Mostly it is found in hard exoskeleton of insects and crustaceans and sometimes in fungal cell wall. It is the second most abundant carbohydrate and the most abundant heteropolysaccharide.
Agar-Agar : It is a galactan consisting of both D and L galactose and is used to prepare bacterial cultures. It is also used as luxative and obtained from cell wall of red algae e.g., Gracilaria, Gelidium etc.
Pectin : It is a cell wall material in collenchyma tissue that may also be found in fruit pulps, rind of citrus fruits etc. It is water soluble and can undergo sol→gel transformation. It contains arabinose, galactose and galacturonic acid.
Gum : It secreted by higher plants after injury or pathogenic attacks. It is viscous and seals the wound. It involves sugars like L-arabinose, D-galactose, D-glucusonic acid. E.g., gum arabic.
FUNCTIONS
- Cellulose, pectin and chitin are constituents in cell wall of higher plants but peptidoglycan in the cell wall of prokaryotes. These are the reserve food material and form a protective covering.
- Fibres obtained are used in making cloth and rope.
- Nitrocellulose and trinitrate cellulose (gun-cotton) are used as explosives.
PROTEINS
- Proteins are polypeptides. These are linear chains of amino acids linked by peptide bonds.
- Essential elements in protein are C , H , O, N. Some contain sulphur(S) and phosphorus (P) also. The structural unit of protein is amino acid.
- A protein is a heteropolymer and not a homopolymer.
- Proteins are polymers of amino acids (Fisher and Hoffmeister). There are approximately 300 amino acids known to exist but only 20 types of amino acids are used in formation of proteins.
- Each amino acid is amphoteric compound because it contains one weak acidic group – COOH and a weak alkaline group – NH2.
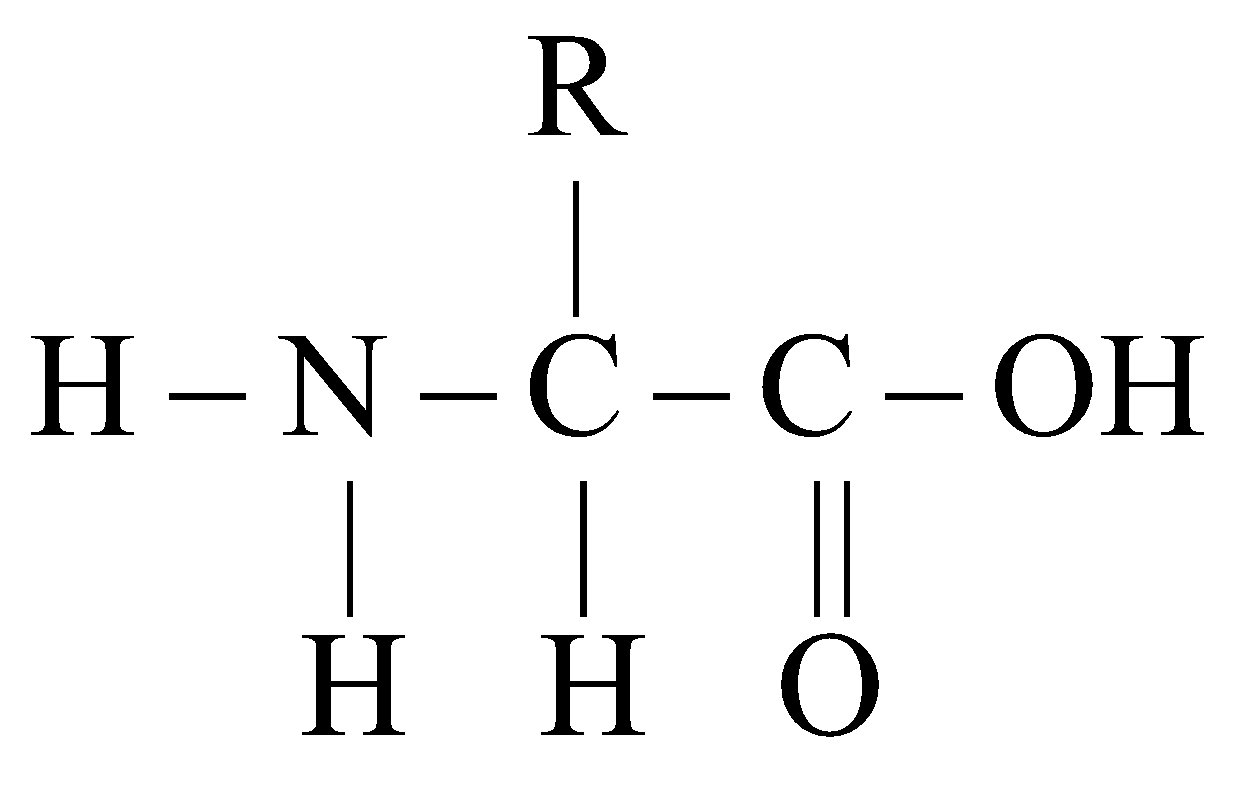
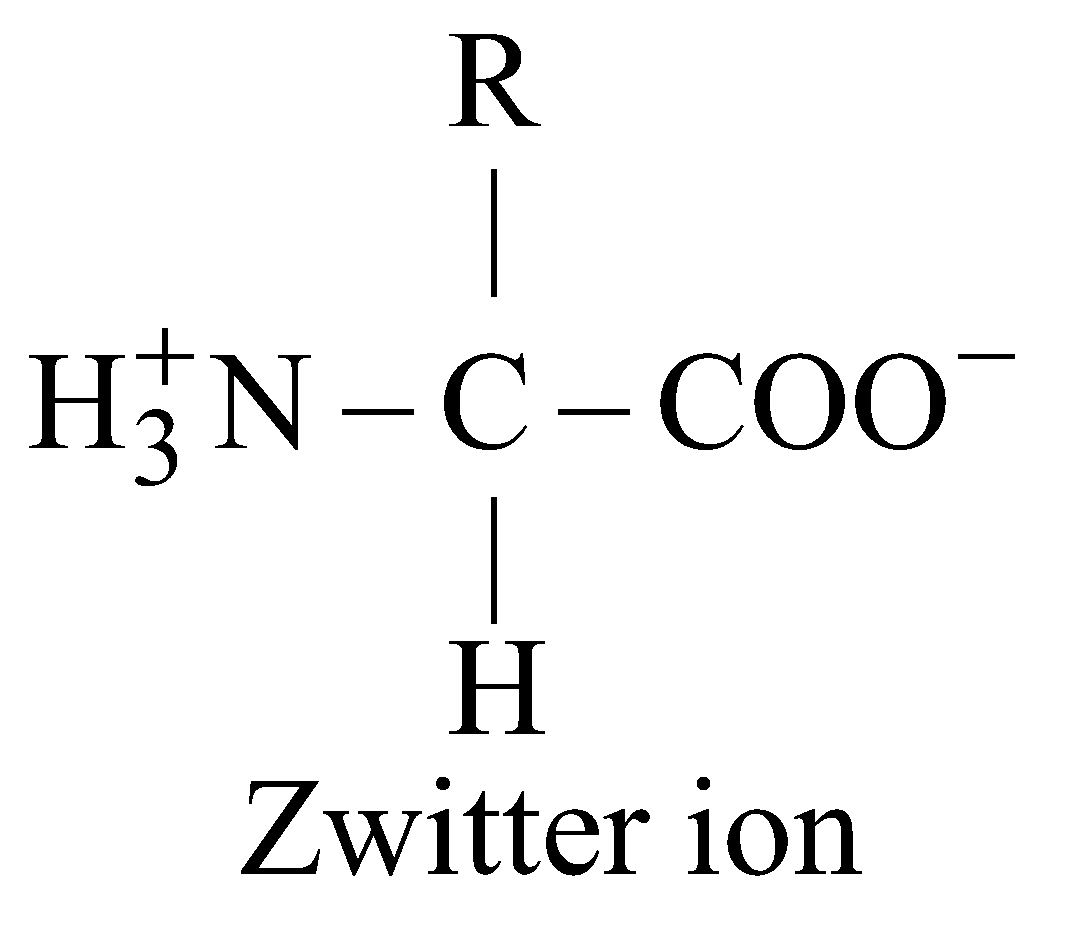
- In protoplasm; free amino acid occurs as ions ( at iso - electric point). Iso - electric point is that point of pH at which amino acids do not move in electric field.
- Amongst proteins, 'collagen' is the most abundant protein of animal world while 'RubisCo' (Ribulose Bisphosphate Carboxylase-Oxygenase) is the most abundant protein of biosphere.
AMINO ACIDS
- The amino acids are 'structural units' as well as 'digestive end products' of proteins.
- Amino acids are organic acids with a carboxyl group
(–COOH) and one amino group (–NH2) on the α -carbon atom. Chemically, these are substituted methane. Carboxyl group attributes acidic properties and amino group gives basic ones. - There are four substituent groups occupying the four valency positions. These are hydrogen, carboxyl group, amino group and a variable group designated as R group.
- In solution, they serve as buffers and help to maintain pH. These are 20 in number, specified in genetic code and universal in viruses, prokaryotes and eukaryotes, which take part in protein synthesis,
- Except glycine, each amino acid has two isomers.
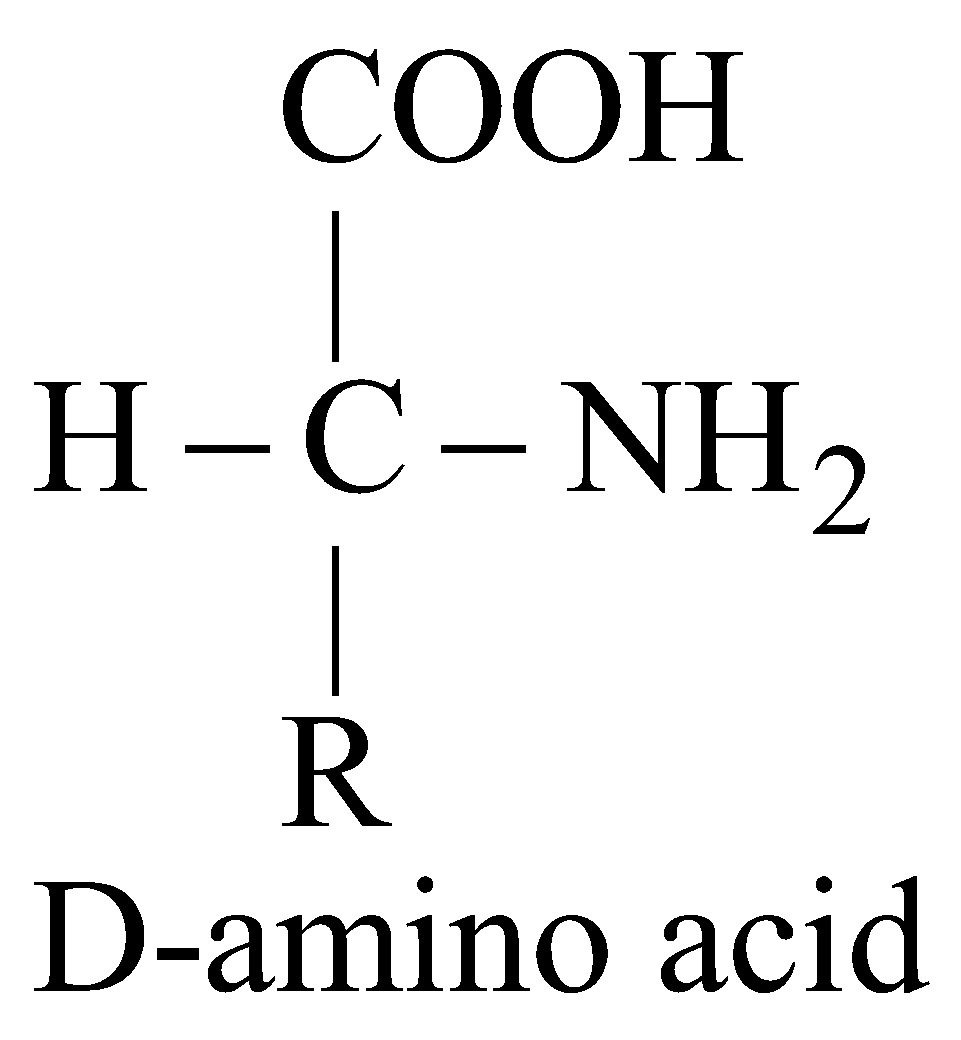

- Eukaryotic proteins have L- amino acid while D- amino acid occurs in bacteria and antibodies.
- Amino acids join with peptide bond and form long chains called polypeptide chains.
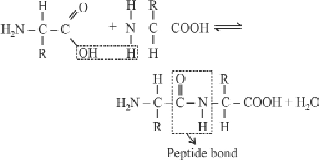
- Peptidyl transferase enzyme catalyses the synthesis of peptide bond.
CLASSIFICATION OF AMINO ACIDS
Amino acids can be classified on the basis of their R (alkyl) group –
- Non-polar R-group : Non-polar side chains consist mainly of hydrocarbons. Any functional groups they contain, are unchanged at physiological pH and are incapable of participating in H–bonding.
E.g., Alanine, valine, leucine, isoleucine, proline, methionine, phenylalanine, tryptophan.
- Polar but uncharged R-group : Polar side chains contain groups that are either charged at physiological pH or groups that are able to participate in hydrogen bonding.
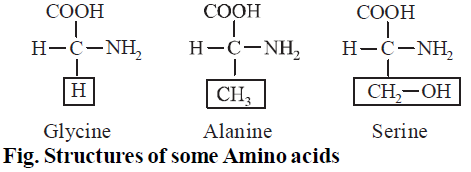
E.g., Glycine, serine, threonine, cysteine, tyrosine, asparagine, glutamine.
- Positively charged polar R-group : These contain 2-amino and 1-carboxyl group.
E.g., Lysine, arginine, histidine (Basic Amino acid)
- Negatively charged polar R-group : These contain 1-amino and 2-carboxyl groups.
Eg. Aspartic acid, glutamic acid (Acidic Amino acid)
PROPERTY OF PROTEIN DEPENDS
ON SEQUENCE OF AMINO ACIDS AND CONFIGURATION OF PROTEIN MOLECULES
- Simple amino acids : These have no functional group in the side chain, e.g., glycine, alanine , leucine, valine etc. Glycine is the simplest amino acid.
- Hydroxy amino acids : These have alcohol group in side chain, e.g., threonine, serine, etc.
- Sulphur containing amino acids : These have sulphur atom in side chain, e.g., methionine, cysteine and cystine.
- Basic amino acids : These have basic group (–NH2) in side chains, e.g., lysine, arginine.
- Acidic amino acids : These have carboxyl groups in side chain, e.g., aspartic acid, glutamic acid.
- Acid amide amino acids : These are the derivatives of acidic amino acids. In this group, one of the carboxyl group has been converted to amide (–CONH2), e.g., asparagine, glutamine.
- Heterocyclic amino acids : These are the amino acids in which the side chain includes a ring involving atleast one atom other than carbon, e.g., histidine, proline and hydroxyproline.
- Aromatic amino acids : These have aromatic group (benzene ring) in the side chain, e.g., phenylalanine, tyrosine and tryptophan.
ON THE BASIS OF REQUIREMENTS
On the basis of the synthesis of amino acids in the body and their requirement, these are categorized as :
- Essential amino acids : These are not synthesized in the body hence need to be provided in the diet, e.g., valine, leucine, isoleucine, threonine, lysine, tryptophan, phenylalanine, methionine etc.
- Semi-essential amino acids : Synthesized partially in the body but not at the rate to meet the requirement of individual, e.g., arginine and histidine.
- Non-essential amino acids : These amino acids are derived from carbon skeleton of lipids and carbohydrate metabolism. In humans, there are 12 non-essential amino acids, e.g., alanine, aspartic acid, cysteine, glutamic acid etc. proline and hydroxyproline have NH (imino group) instead of NH2 hence are called imino acids.
NOTES
- All the amino acids are laevo-rotatory, except glycine which is non-rotatory.
- Amino acids which participate in protein synthesis are called protein amino acids. Amino acids which do not participate are called non-protein amino acids, e.g. GABA, ornithine, citrulline, thyroxine etc.
CONFIGURATION OF PROTEIN MOLECULE
(1) PRIMARY STRUCTURE
A straight chain of amino acids linked by peptide bonds form primary structure of proteins. The first (or left) amino acid is called N—terminal (–NH2 group.) amino acid, and the last (or right) amino acid is called C-terminal (–COOH group) amino acid. Such proteins are non functional proteins. This structure of proteins is most unstable. Newly formed proteins on ribosomes have primary structure.
(2) SECONDARY STRUCTURE
Protein molecules of secondary structure are spirally coiled. The spiral is stabilized by straight hydrogen bonds between imide group (– NH –) of one amino acid and carbonyl group
(– CO) of fourth amino acid residue. In this way, all the imide and carbonyl groups become hydrogen bonded.
(– CO) of fourth amino acid residue. In this way, all the imide and carbonyl groups become hydrogen bonded.
- α-helix : Right handed rotation of spirally coiled chain with approximately 3½ amino acids in each turn. This structure has intramolecular hydrogen bonding i.e. between two amino acids of the same chain e.g., keratin, myosin, tropomyosin.
- β-helix or pleated sheath structure : Protein molecule has zig - zag structure. Two or more protein molecules are held together by intermolecular hydrogen bonding. The polypeptide chain may be parallel or antiparallel, e.g. Keratin protein in birds (β– sheets parallel) and silk protein (fibroin) with antiparallel β–sheets.
- Proteins of secondary structure are insoluble in water and fibrous in appearance.
- Keratin is a fibrous, tough, resistant to digestion sclero-protein. Hardness of keratin is due to abundance of cysteine amino acid in its structure.
(3) TERTIARY CONFIGURATION OR STRUCTURE
Proteins of tertiary structure are highly folded to give a globular appearance. These are soluble in water (colloid solution) giving us a 3–dimensional view of a protein. Tertiary structure is absolutely necessary for the many biological activities of proteins. Tertiary structure is stabilised by five types of bonds:
- Peptide bonds : strongest bond in proteins.
- Hydrogen bonds : These occur between hydrogen and oxygen atoms of various groups.
- Disulphide bond : These bonds form between - SH group of amino acids (e.g., methionine, cysteine). These bonds are second strongest bond and stabilise the tertiary structure of protein.
- Hydrophobic bonds : Present between amino acids which have hydrophobic side chains, e.g. aromatic amino acids.
- Ionic bonds : Formation of ionic bond occurs between two opposite ends of a protein molecule due to electrostatic attraction. Majority of proteins and enzymes in protoplasm exhibit tertiary structure.
(4) QUATERNARY STRUCTURE
Two or more polypeptide chains of tertiary structure united by different types of bonds to form quaternary structure of protein. Different polypeptide chains may be similar (e.g., lactic-dehydrogenase) or dissimilar types (e.g., haemoglobin, insulin). Quaternary structure is most stable structure of protein.
NOTES
Adult human haemoglobin consists of 4 subunits. Two of these are identical to each other. Hence, two subunits of α type and two subunits of β type together constitute the human
haemoglobin (Hb).
haemoglobin (Hb).
SIGNIFICANCE OF STRUCTURE OF PROTEIN
- The most important constituents of animals are proteins and their derivatives.
- In an acidic medium, the – COO– group of protein converts to – COOH and the protein itself becomes positively charged. In contrast, in an alkaline medium the – NH3+ group of protein changes to – NH2 + H2O and as a result it becomes negatively charged. Therefore, at a specific pH, a protein will possess an equal number of both negative and positive charges and it is at this specific pH, a protein becomes soluble.
- If the pH changes towards either acidic or alkaline side, then the protein begins to precipitate. This property of protein has a great biological significance. The cytoplasm of cells of organism has an approximate pH of 7 but the pH of proteins present in it is about 6 and thus, the proteins are present in a relatively alkaline medium. Therefore, the proteins are negatively charged and also are not in a fully dissolved state. It is because of this insolubility, proteins form the structural skeleton. Similarly, the pH of nucleoplasm is about 7 but the pH of proteins, namely, histones and protamines, in it is relatively more. Therefore, as a result they are positively charged and do not remain fully dissolved in the nucleoplasm forming minute organelles, the most important being the chromosomes.
- Such compounds which exhibit both acidic and alkaline properties are called amphoteric compounds or zwitterions. In the protoplasm, this dual property of proteins is utilized for neutralization of strong acids and alkalis since the protein acts as an ideal buffer in either of the situations.
Besides changes in pH, salts, heavy metals, temperature, pressure, etc. also cause precipitation of proteins.
TYPES OF PROTEINS
SIMPLE PROTEINS
Proteins which are composed of only amino acids.
- Fibrous Proteins : E.g., Collagen, elastin, keratin
- Globular Proteins : E.g., Albumin, histones, globin, protamines, prolamines (Glaidin, Gluten, Zein), Gluteline (slimy part of gluten of wheat).
CONJUGATED PROTEINS
Formed by the binding of a simple protein with a non-protein part (prosthetic group).
- Nucleoproteins - Proteins attached to nucleic acids, e.g., chromatin, ribosomes etc.
- Chromoprotein - Proteins with pigment or coloured, e.g., haemoglobin, haemocyanin, cytochromes etc.
- Lipoprotein - Proteins combined with lipids, e.g., cell membrane, lipovitelline of yolk.
- Phosphoproteins - Proteins containing phosphorus – e.g., casienogen, pepsin, ovovitelline, phosvitin.
- Glycoproteins – Proteins combined with carbohydrates, e.g., hormones like FSH, LH, TSH and HCG, blood group antigens, serum protein etc.
- Metallo-protein : Proteing with metal ions –e.g., Cu-tyrosinase, Zn-carbonic anhydrase, Mn-arginase, Mo-xanthine oxidase, Mg-kinase.
DERIVED PROTEINS
These form by denaturation or hydrolysis of protein.
- Primary derived proteins are denaturation products of normal proteins, e.g., fibrin, myosin.
- Secondary derived proteins are digestion products of proteins, e.g., proteoses, peptones.
FUNCTIONS OF PROTEINS
- Formation of cells and tissues for growth.
- Repairing of tissues.
- Formation of hormones.
- For muscle contraction (e.g., actin, myosin).
- Formation of enzymes.
- Help in blood clotting.
- For transport (e.g., haemoglobin, transferrin).
- For defence against infections (e.g., antibodies).
- Form hereditary material – nucleoproteins.
- For storage (e.g., myoglobin and ferritin).
- For support (e.g., collagen and elastin).
NUCLEIC ACIDS
- Nucleic acids are the polymers of nucleotide made up of carbon, hydrogen, oxygen, nitrogen and phosphorus which control the basic functions of the cell.
- Miescher discovered nucleic acids in the nucleus of pus cell and called it nuclein. The name nucleic acid was proposed by Altman.
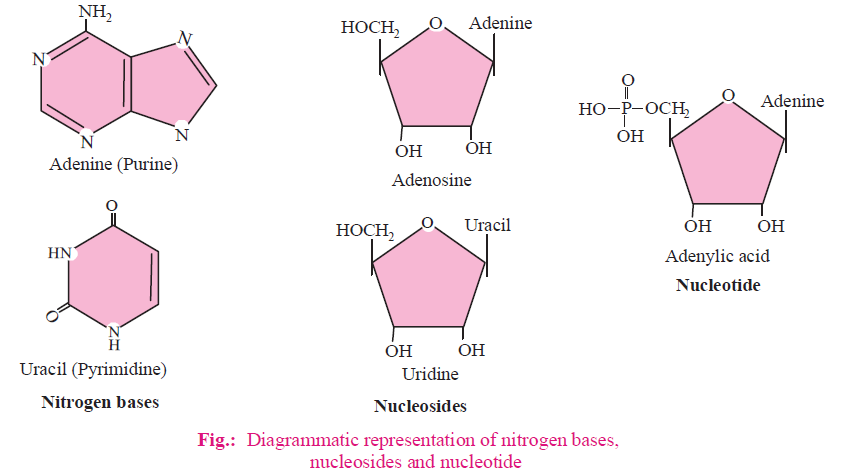
- On the basis of structure, nitrogen bases are broadly of two types :
- Pyrimidines : These consist of one pyrimidine ring. Skeleton of ring is composed of two nitrogen and four carbon atoms. E.g., cytosine, thymine (in DNA) and uracil (in RNA).
- Purines : These consist of two rings i.e. one pyrimidine ring (2N + 4C) and one imidazole ring (2N + 3C). E.g., adenine and guanine.
PENTOSE SUGAR
- Nitrogen base forms bond with first carbon of pentose sugar to form a nucleoside, nitrogen of third place (N3) forms bond with sugar in case of pyrimidines while in purines nitrogen of ninth place (N9) forms bond with sugar.
- Phosphate : Phosphate forms ester bond (covalent bond) with fifth carbon of sugar to form a complete nucleotide.
- When nitrogen bases are found attached to a pentose sugar, then they are called nucleosides, e.g., adenosine, guanosine, thymidine, uridine and cytidine.
- Nucleotides are phosphorylated nucleosides. These are formed by condensation of a pentose sugar, a nitrogen base and at least one phosphoric acid residue, e.g., adenylic acid, thymidylic acid, guanylic acid, uridylic acid and cytidylic acid.
- Nucleic acids like DNA and RNA consist of nucleotides only. DNA and RNA function as genetic material.
DNA (DEOXYRIBONUCLEIC ACID)
- DNA was first identified and isolated by Friedrich Miescher. A nucleic acid containing deoxyribose is called deoxyribonucleic acid (DNA).
- In DNA, pentose sugar is deoxyribose sugar and four types of nitrogen bases are Adenine (A), Thymine (T), Guanine (G) and Cytosine (C).
- Wilkins and Franklin studied DNA molecule with the help of X-ray crystallography.

- With the help of this study, Watson and Crick (1953) proposed a double helix model for DNA. For this model, Watson, Crick and Wilkins were awarded noble prize in 1962.
- According to this model, DNA is composed of two polynucleotide chains. Both polynucleotide chains are complementary and anti-parallel to each other.
- In both strands of DNA, direction of phosphodiester bond is opposite, i.e., if direction of phosphodiester bond in one strand is 3'-5' then it is 5'-3' in another strand.
- Both strands of DNA are held together by hydrogen bonds. These hydrogen bonds are present between nitrogen bases of both strands.
- Adenine binds to Thymine by two hydrogen bonds and Cytosine binds to Guanine by three hydrogen bonds.
- Chargaff’s equivalence rule : In a double stranded DNA, amount of purine nucleotides is equal to amount of pyrimidine nucleotides.
Purine = Pyrimidine
[A] + [G] = [T] + [C]
Base ratio = 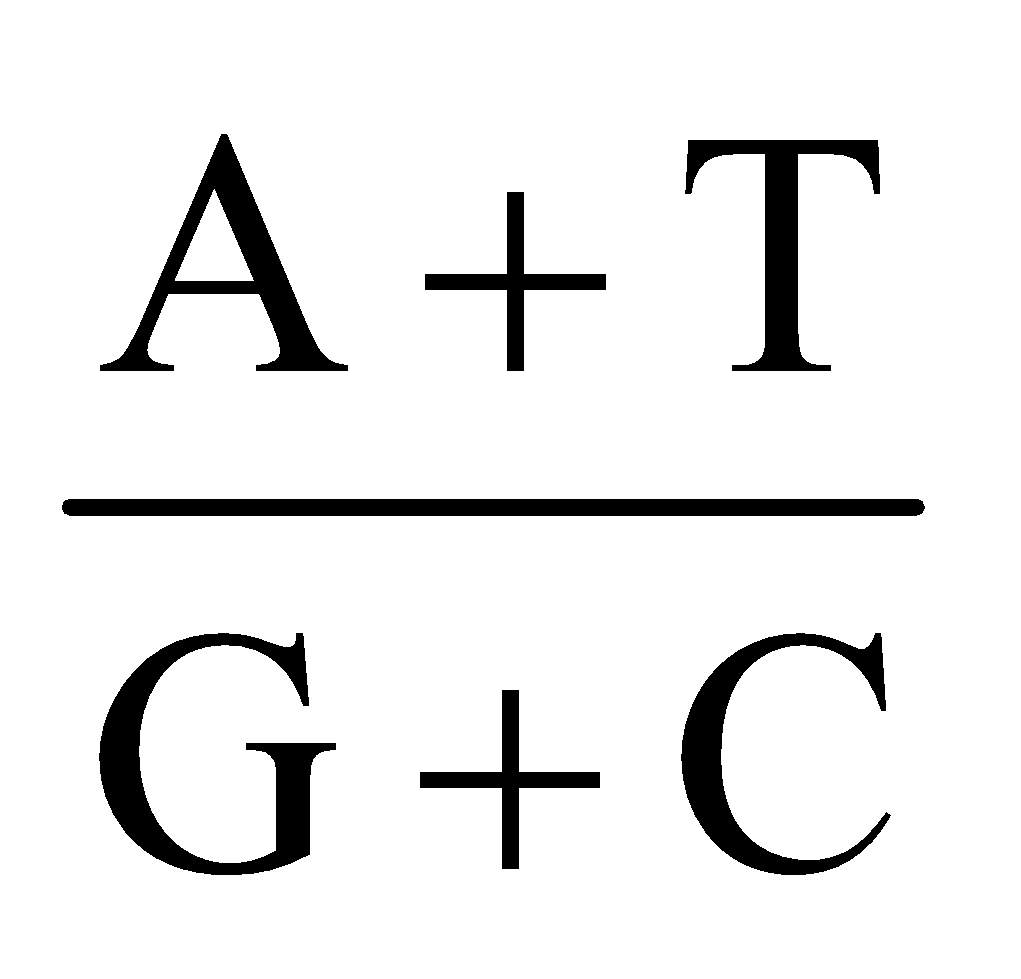 = constant for a given species.
= constant for a given species.
In DNA , A + T > G + C ⇒ A – T type DNA.
Base ratio of A – T type of DNA is more than one.
E.g., Eukaryotic DNA.
In DNA, G + C > A + T ⇒ G – C type DNA.
Base ratio of G - C type of DNA is less than one.
E.g., Prokaryotic DNA.
- Melting point of DNA depends on G – C contents.
More G – C content means more melting point.
Tm (melting temperature) of prokaryotic DNA > Tm of eukaryotic DNA.
CONFIGURATION OF DNA MOLECULE
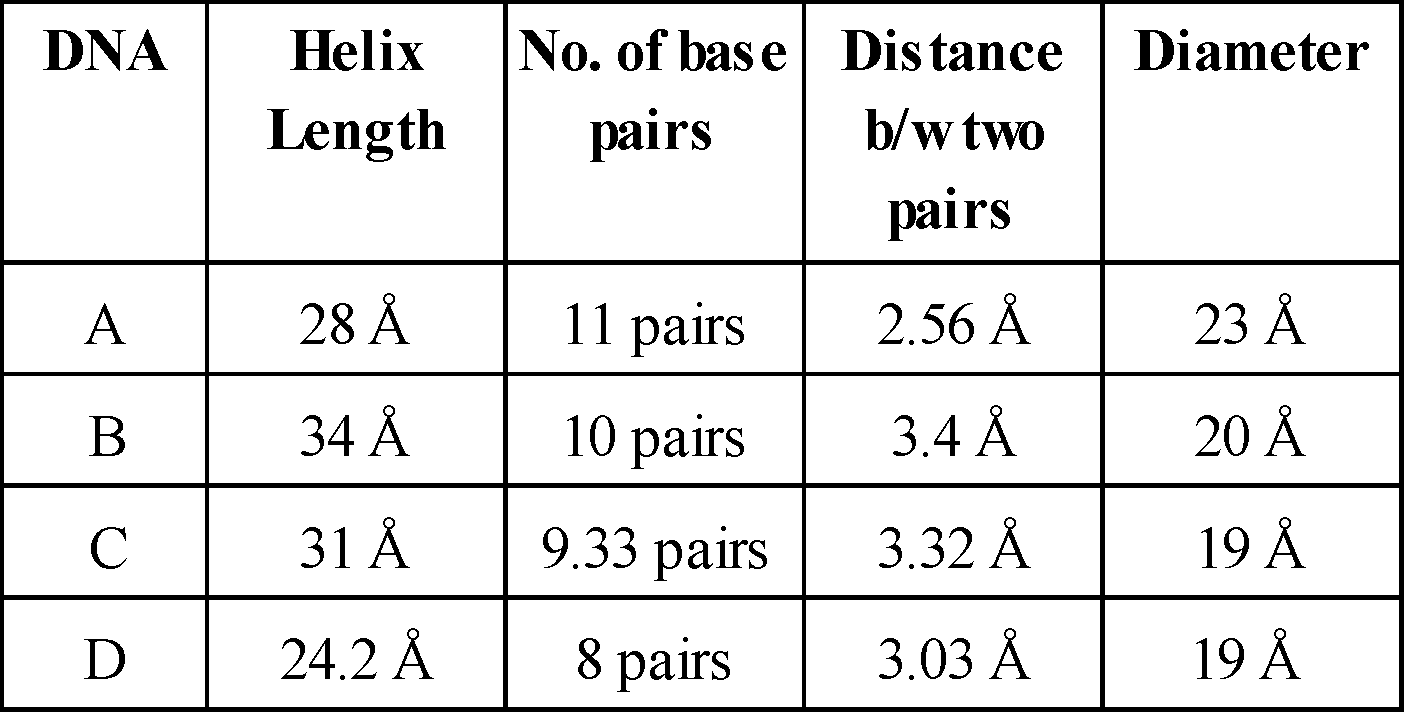
- Two strands of DNA are helically coiled like a revolving ladder. Backbone of this ladder (Reiling) is composed of phosphates and sugars while steps (bars) are composed of pairs of nitrogen bases. The strand turns 36°.
- Distance between two successive steps is 3.4 Å, In one complete turn of DNA molecule, there are 10 such steps
(10 pairs of nitrogen bases). So, the length of one complete turn is 34 Å. This is called helix length. - Diameter of DNA molecule i.e., distance between phosphates of two strands is 20Å.
- Distance between sugar of two strands is 11.1Å.
- Length of hydrogen bonds between nitrogen bases is 2.8-3.0Å. Angle between nitrogen base and C1 carbon of pentose is 51°.
- Molecular weight of DNA is 106 to 109 dalton.
- In the nucleus of eukaryotes, the DNA is associated with histone proteins to form nucleoprotein.
- Bond between DNA and histone is salt linkage (Mg+2).
- DNA in chromosomes is linear while in prokaryotes, mitochondria and chloroplast, it is circular.
- In φ × 174 bacteriophage, the DNA is single stranded and circular.
- G-4, S-13, M-13, F1 and Fd - Bacteriophages also contain ss (single stranded) - circular DNA.
TYPES OF DNA
On the basis of direction of twisting, there are two types of DNA:
RIGHT HANDED DNA
- Clockwise twisting e.g. The DNA for which Watson and Crick proposed model was B - DNA.
- Other exmples of right handed DNA are –
LEFT HANDED DNA
- Anticlockwise twisting e.g. Z-DNA-discovered by Alexander Rich.
- Phosphate and sugar backbone is zig-zag.
- Units of Z-DNA are dinucleotides (purine and pyrimidine in alternate order)
- Helix length 45.6 Å, Diameter - 18.4 Å
- No. of base pairs : 12 (6 dimers)
- Distance between base pairs = 3.75 Å
FUNCTIONS OF DNA
DNA is vital for all living beings – It is important for inheritance, coding for proteins and the genetic instruction guide for life and its processes. DNA holds the instructions for an organisms or each cell's development and reproduction and ultimately death.
NOTES
- DNA molecule is Dextrorotatory while RNA molecule is Laevorotatory.
- C-value = Total amount of DNA in a genome or haploid set of chromosomes.
RNA (RIBONUCLEIC ACID)
Structure of RNA is fundamentally the same as DNA, but there are some differences. The differences are :
- In place of deoxyribose sugar of DNA, ribose sugar is present in RNA.
- In place of nitrogen base thymine present in DNA, nitrogen base uracil is present in RNA.
- RNA is made up of only one polynucleotide chain i.e., RNA is single stranded.
Exception : RNA found in reo-virus is double stranded, i.e., it has two polynucleotide chains.
TYPES OF RNA
GENETIC RNA OR GENOMIC RNA
In the absence of DNA, sometimes RNA working as genetic material and genomic RNA transfer information from one generation to the next generation.
E.g., Reovirus and Tobacco Mosaic Virus (TMV).
NON-GENETIC RNA
3 types : (a) r - RNA (b) t - RNA (c) m - RNA
(1) Ribosomal RNA (r - RNA)
- This RNA is 80% of the cells total RNA.
- It is found in ribosomes and is produced in the nucleolus.
- At the time of protein synthesis, r-RNA provides attachment sites to t-RNA and m-RNA and attaches them on the ribosome.
(2) Transfer - RNA (t-RNA) / soluble RNA (sRNA) / adapter RNA
- It is 10-15% of total RNA.
- It is synthesized in the nucleus by DNA.
(3) Messenger RNA (m -RNA)
- The m- RNA is 1-5% of the cell’s total RNA.
- It is produced by genetic DNA in the nucleus. This process is known as transcription.
DYNAMIC STATE OF BODY CONSTITUENTS - CONCEPT OF METABOLISM
- Metabolism is the set of life sustaining chemical transformations within the cells of living organisms. These enzyme - catalyzed reactions allows organisms to grow, reproduce, maintain their structures, and respond to their environments.
- A few examples for such metabolic transformations are : removal of CO2 from amino acids making an amino acid into an amine, removal of amino group in a nucleotide base; hydrolysis of a glycosidic bond in a disaccharide, etc.
- It is divided into 2 classes : Catabolism breaks down organic matter, e.g., to harvest energy in cellular respiration. Anabolism uses energy to construct components of cells such as proteins and nucleic acids.
- Metabolites are converted into each other in a series of linked reactions by a sequence of enzymes called metabolic pathways.
- In metabolic reactions, every chemical reaction is catalysed reaction. There is no uncatalysed metabolic conversion in living systems.
- Metabolic Basis for Living
- Metabolic pathways can lead to a more complex structure from a simpler structure (for example, acetic acid becomes cholesterol) or to a simpler structure from a complex structure (for example, glucose becomes lactic acid in our skeletal muscles).
- Living organisms have learnt to trap energy liberated during degradation and store it in the form of chemical bonds. As and when needed, this bond energy is utilised for biosynthetic, osmotic and mechanical work that we perform. The most important form of energy currency in living systems is the bond energy in a chemical called adenosine triphosphate (ATP).
ENZYMES
- Enzymes are biocatalysts made up of proteins (except ribozyme) which increases the rate of biochemical reactions by lowering down the activation energy, but does not affect the nature of final product.
- The term enzyme (meaning in yeast) was used by Willy Kuhne (1878) while working on fermentation.
- Zymase (from yeast) was the first discovered enzyme by Buchner.
- The first purified and crystalized enzyme was urease
(by J.B. Sumner) from Canavalia/Jack Bean (Lobia plant) and suggested that enzymes are proteins.
CHARACTERISTICS OF ENZYMES
- All enzymes are proteins, but all proteins are not enzymes. Enzymatic proteins consist of 20 amino acids.
- All enzymes are tertiary and globular proteins (isoenzymes quaternary protein). Their tertiary structure is very specific and important for their biological activity.
- Enzymes accelerate the rate of reaction without undergoing any change in themselves. Enzymes lower the activation energy of substrate or reactions.
- Enzymes are macromolecules of amino acids which are synthesized on ribosomes under the control of genes.
- Molecular weight of enzymes are high and these are colloidal substances.
- Enzymes are very sensitive to pH and temperature. Optimum temperature for enzymes is 20-35°C. Most of the enzymes are active at neutral pH, hydrolytic enzymes of lysosomes are active at acidic pH (5).
- Enzymes are required in very minute amounts for biochemical reactions.
- Their catalytic power is represented by Michaelis Menten constant or Km constant and turn over number. ‘‘The number of substrate molecules converted into products per unit time by one molecule of the enzyme in favourable conditions is called turnover number.’’
- Enzymes are very specific to their substrate or reactions.
STRUCTURE OF ENZYMES
- Simple enzymes : These are exclusively made up of protein i.e., simple proteins.
E.g., pepsin, trypsin, papain.
- Conjugated enzymes : Enzymes are composed of one or several polypeptide chains. However, there are a number of cases in which non-protein constituents called co-factors are bound to the enzyme to make the enzyme catalytically active. The protein part of the enzyme is called apoenzyme. There are 3 kinds of cofactors which are given as follows :
- Co-enzymes : These are non-protein organic groups, which are loosely attached to apoenzymes. These are generally made up of vitamins, e.g., coenzyme nicotinamide adenine dinucleotide (NAD), nicotinamide adenine dinucleotide phosphate (NADP) contains the vitamin niacin, coenzyme A contains pantothenic acid, flavin mononucleotide (FMN), flavin adenine dinucleotide (FAD) contains riboflavin (Vitamin B2), and thiamine pyrophosphate (TPP) contains thiamine (Vitamin B1).
- Prosthetic group : When non-protein part is tightly or firmly attached to apoenzyme. These are organic compounds. E.g., in peroxidase and catalase, which catalyze the breakdown of H2O2 to H2O and O.
- Metal ions : Metal ions play an essential role in regulating the activity of enzymes by forming coordination bonds with side chains at the active site and at the same time form one or more coordination bonds with the substrate. E.g., Mn, Fe, Co, Zn, Ca, Mg, Cu.
- Active site : Specific part of enzyme at which specific substrate is to bind and catalyse the reaction is known as an active site. Active site of enzyme is made up of very specific sequence of amino acids which is, determined by genetic codes.
- Allosteric site : Besides the active site, some enzymes possess additional sites, at which chemicals other than substrate (allosteric modulators) bind. These sites are known as allosteric sites and enzymes with allosteric sites are called as allosteric enzymes, e.g., hexokinase, phosphofructokinase.
TERMS RELATED TO ENZYMES
- Endoenzymes : Enzymes which are functional only inside the cells.
- Exoenzymes : Enzymes catalysed the reactions outside the cell. E.g., enzymes of digestion, some enzymes of insectivorous plants, zymase complex of fermentation.
- Proenzyme/Zymogen : These are precursors of enzymes or inactive forms of enzymes.
E.g., Pepsinogen, Trypsinogen, etc.
- Iso-enzymes : Enzymes having similar action, but little difference in their molecular configuration are called isoenzymes. 16 forms of α-amylase of wheat and 5 forms of LDH (Lactate dehydrogenase) are known. These all forms are synthesised by different genes.
- Inducible enzymes : When formation of enzyme is induced by substrate availability. E.g., Lactase, Nitrogenase, β-galactosidase.
- Biodetergents : Enzymes used in washing powders are known as bio-detergents, e.g., amylase, lipase, proteolytic enzymes.
- Housekeeping / constitutive enzymes : These enzymes are always present in constant amount and are also essential to cell.
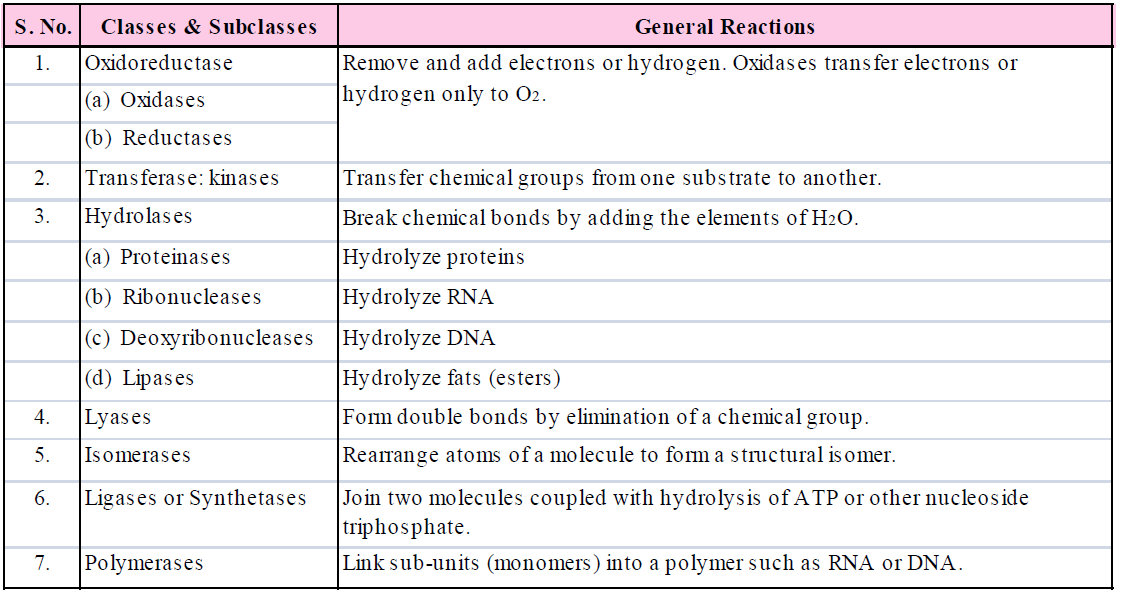
NOMENCLATURE AND CLASSIFICATION OF ENZYMES
MECHANISM OF ENZYME ACTION
- Energy is required to convert the inert molecules into the activated state. The amount of energy required to raise the energy of molecules at which chemical reaction can occur is called activation energy.
- Enzymes act by decreasing the activation energy so that the number of activated molecules is increased at lower energy levels. If the activation energy required for the formation of the enzyme-substrate complex is low, many more molecules can participate in the reaction than would be the case if the enzymes were absent.

MODE OF ACTION OF ENZYME
(1) LOCK & KEY THEORY OR TEMPLATE THEORY
- The theory was given by Emil Fischer.
- According to this theory, active sites of enzymes serve as a lock into which the reactant substrate fits like a key. Enzymes have specific sites where a particular substrate can only be attached. This model accounts for enzyme specificity.

(2) ENZYME - SUBSTRATE COMPLEX THEORY
In 1913, Michaelis and Menten proposed that for a catalytic reaction to occur it is necessary that the enzyme and substrate bind together to form an enzyme substrate complex.
It is amazing that the enzyme-substrate complex breaks up into chemical products different from that which participated in its formation (i.e., substrates). On the surface of each enzyme, there are many specific sites for binding substrate molecules called active sites or catalytic sites.
(3) INDUCED FIT THEORY
- This hypothesis was proposed by Koshland (1959).
- According to this theory, active site is not static but it undergoes a conformational change which is induced by specific substrate.

FACTORS / AFFECTING ENZYME ACTION
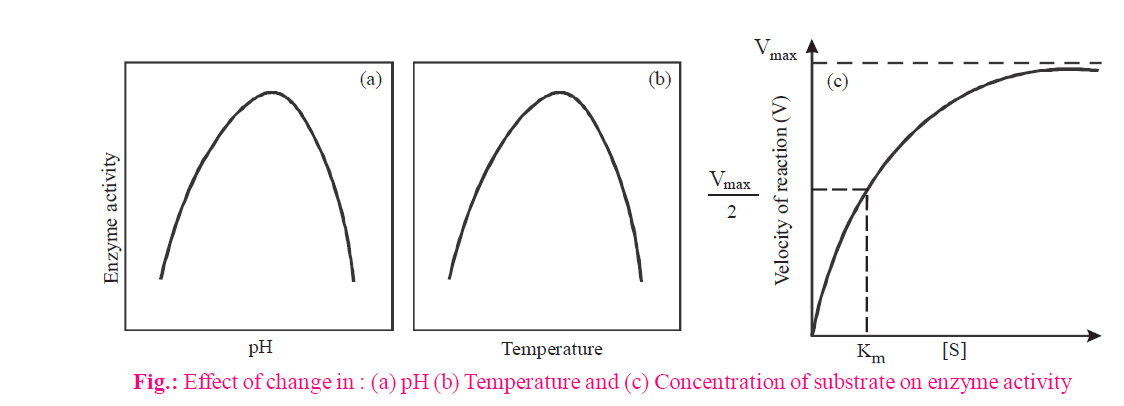
The activity of an enzyme can be affected by a change in the conditions which can alter the tertiary structure of the protein. These include temperature, pH, change in substrate concentration or binding of specific chemicals that regulate its activity.
- pH : Enzymes are very sensitive to pH. Each enzyme shows its highest activity at optimum pH. Activity declines both below and above the optimum value.
- Temperature : Low temperature preserves the enzyme in a temporarily inactive state whereas high temperature destroys enzymatic activity because proteins are denatured by heat. Generally all enzymes perform better at body temperature of an organism.
- Enzyme concentration : The rate of reaction is directly proportional to enzyme concentration. An increase in enzyme concentration will cause a rise in the rate of reaction upto a point and after which the rate of reaction becomes constant. Increasing the enzyme concentration, increases the number of available active sites.
- Substrate concentration : Increase in substrate concentration increases the activity of enzymes until all the active sites of enzymes are saturated by the substrate molecules. Therefore, the substrate molecules occupy the active sites vacated by the products and cannot increase the rate of reaction further.
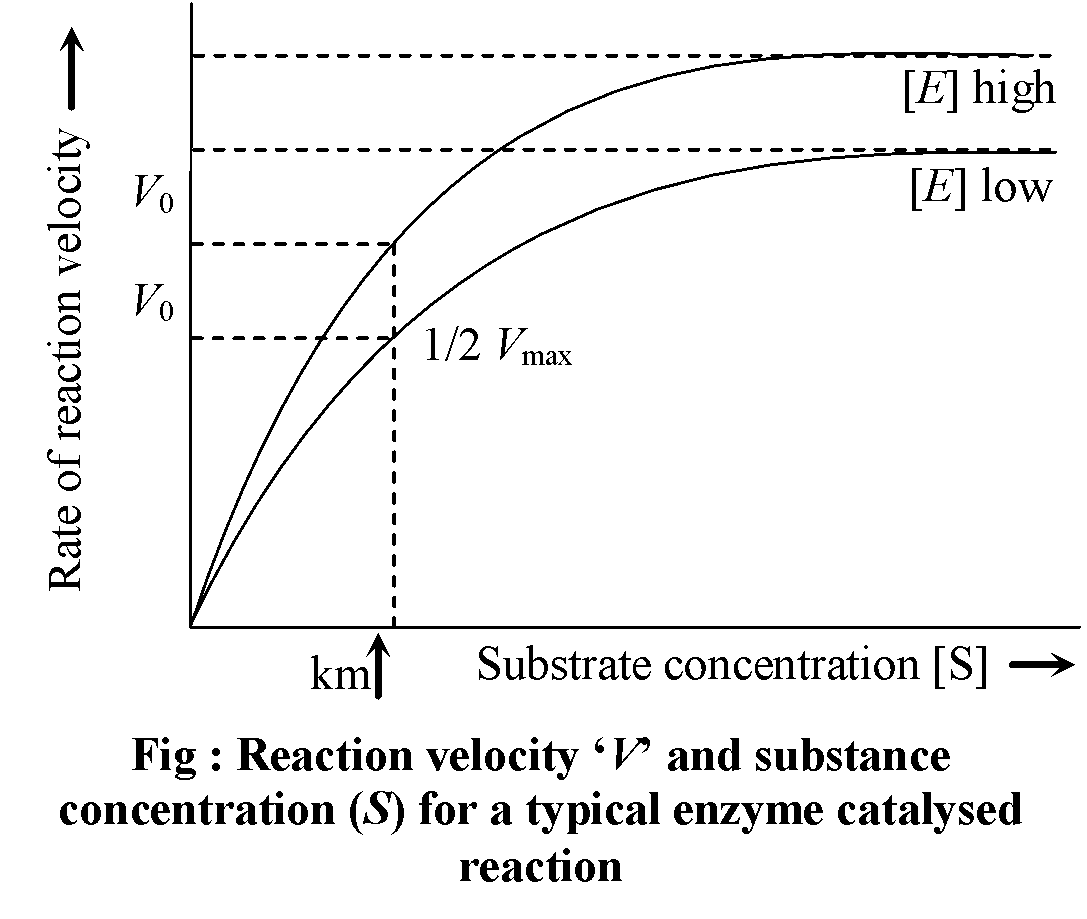
Km CONSTANT (MICHAELIS & MENTEN CONSTANT)
- Km constant of an enzyme is the concentration of substrate at which rate of reaction of that enzyme attains half of its maximum velocity. It is given by Michaelis & Menten. The value of Km should be lower for an enzyme.
- Km exhibits catalytic activity of an enzyme.
- Km value differs from substrate to substrate because different enzymes differ in their affinity towards different substrates. A high Km indicates low affinity while a low Km shows strong affinity.
- Protease acts on different proteins. So its Km value differs from protein to protein.
The Michaelis Menten equation describes how rate of reaction relatively varies with substrate concentration
V0 = 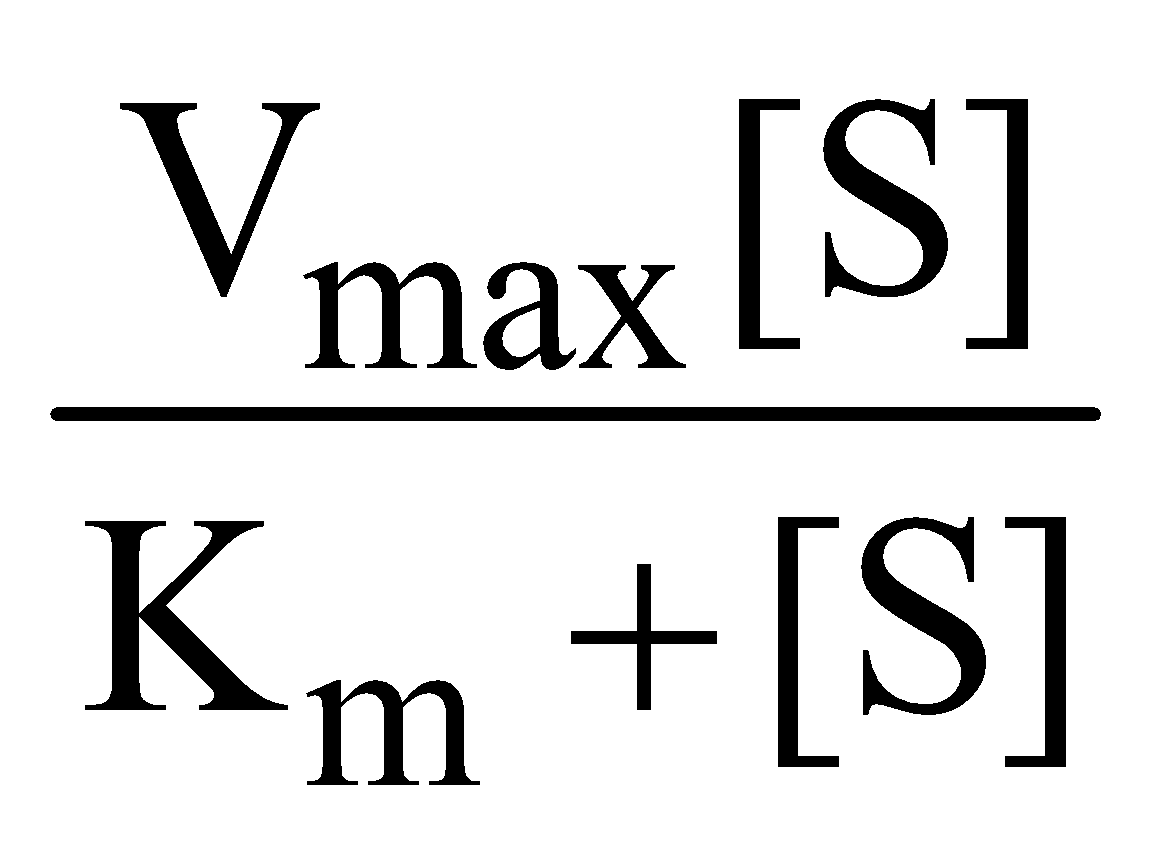
Where Vo is the rate of initial reaction; Vmax is the maximum relative or the reaction rate with excess substrate; Km is the Michaelis constant = K2+K3/K1; [S] is the substrate concentration.
The above reaction shows that the greater the affinity between an enzyme and its substrate, the lower the Km (in units moles per litre) of the enzyme substrate reaction. Stated inversely, 1/Km is the measure of affinity of the enzyme for its substrate.
Post a Comment